Motivation
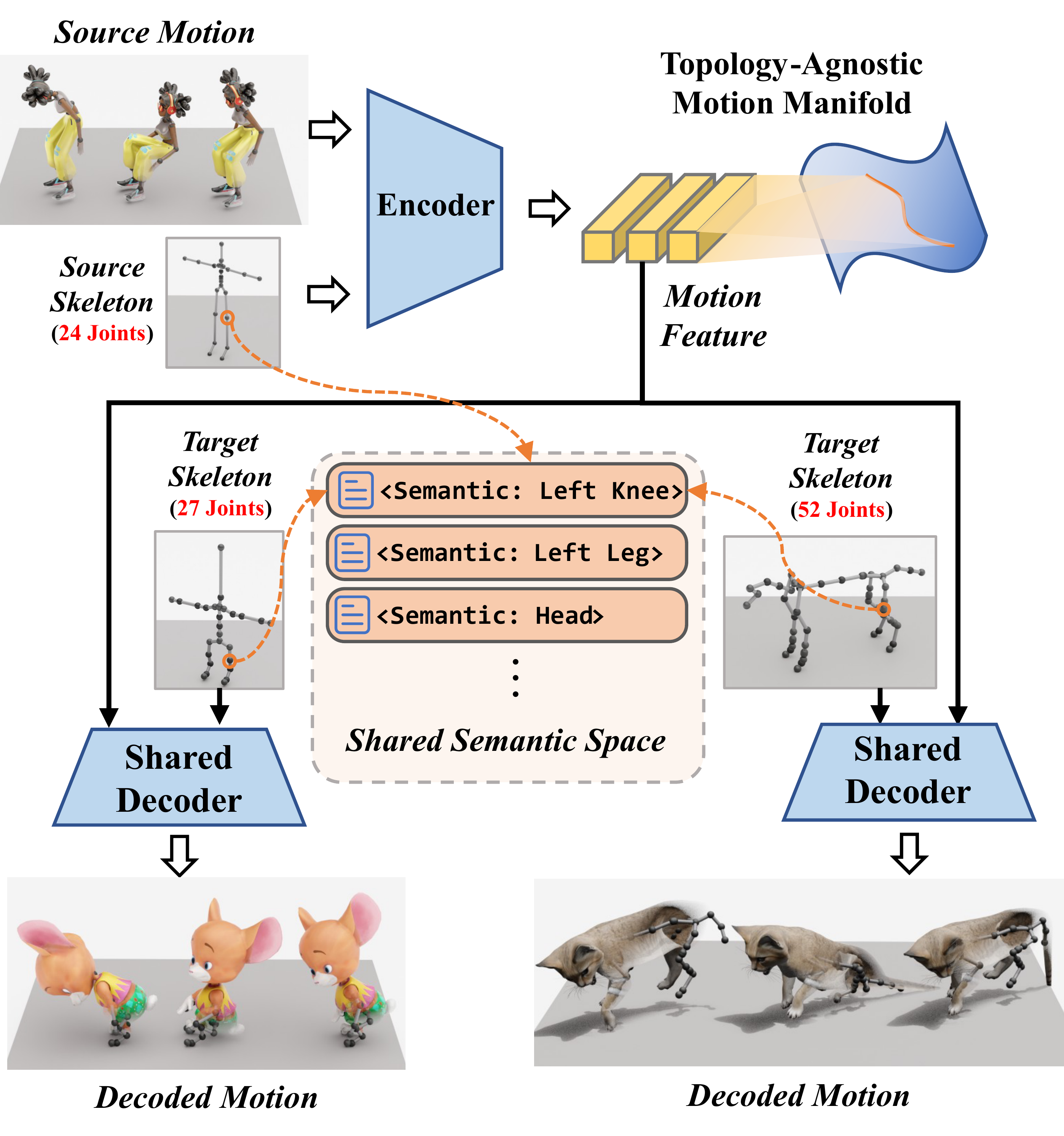
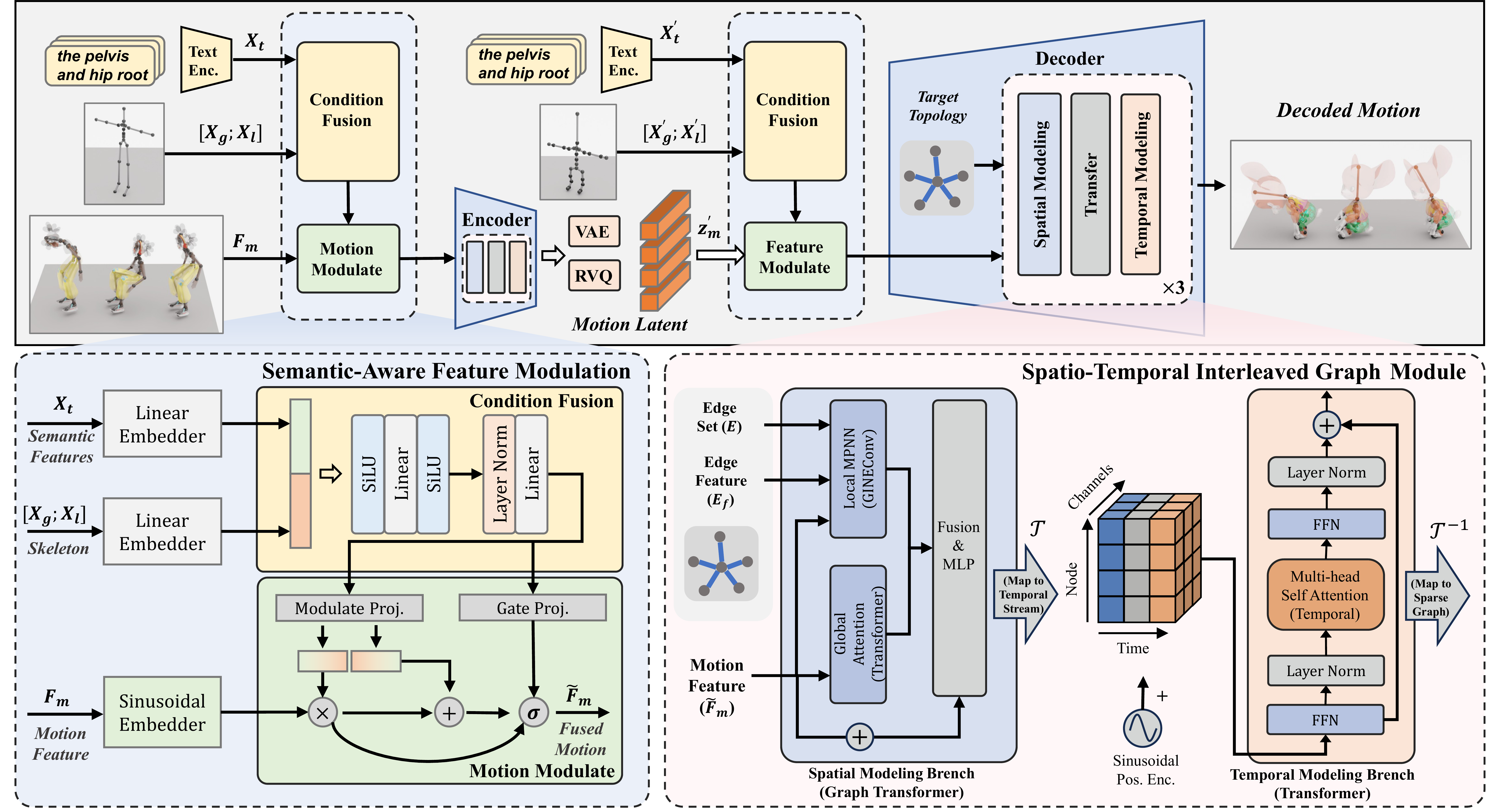
Generalizing motion representation across diverse characters remains challenging due to significant topological variations in skeletal structures across datasets and species, which hinders the development of scalable generative models. To bridge this gap, we propose a Semantic-Aware Topology-Agnostic framework that learns a unified latent manifold shared by disparate species. Unlike methods relying on fixed hierarchies or rigid padding strategies, our approach leverages a semantic modulation mechanism to align functional joint correspondences, thereby decoupling motion from topology. This design enables the construction of a continuous, generative-friendly motion space from large-scale, unaligned raw BVH data. Experiments on human and animal datasets demonstrate that our framework achieves high-fidelity reconstruction and supports downstream text-to-motion tasks. Notably, the model enables zero-shot cross-species retargeting without paired data.
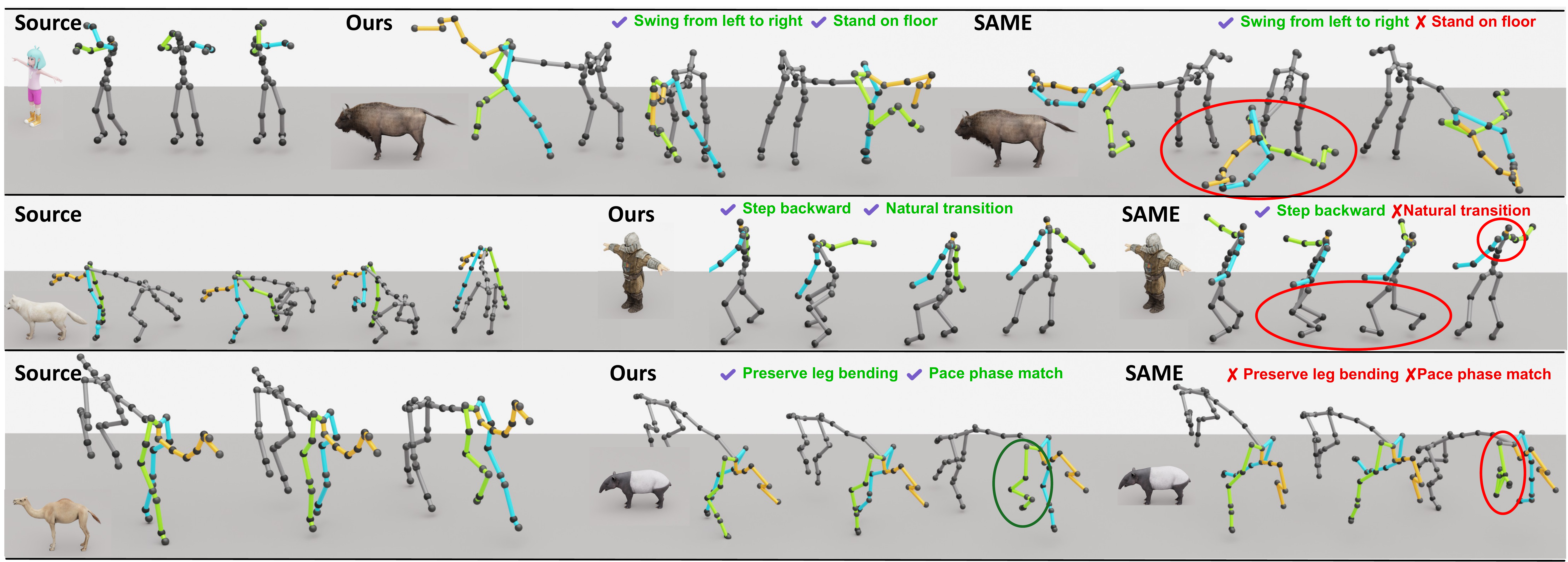
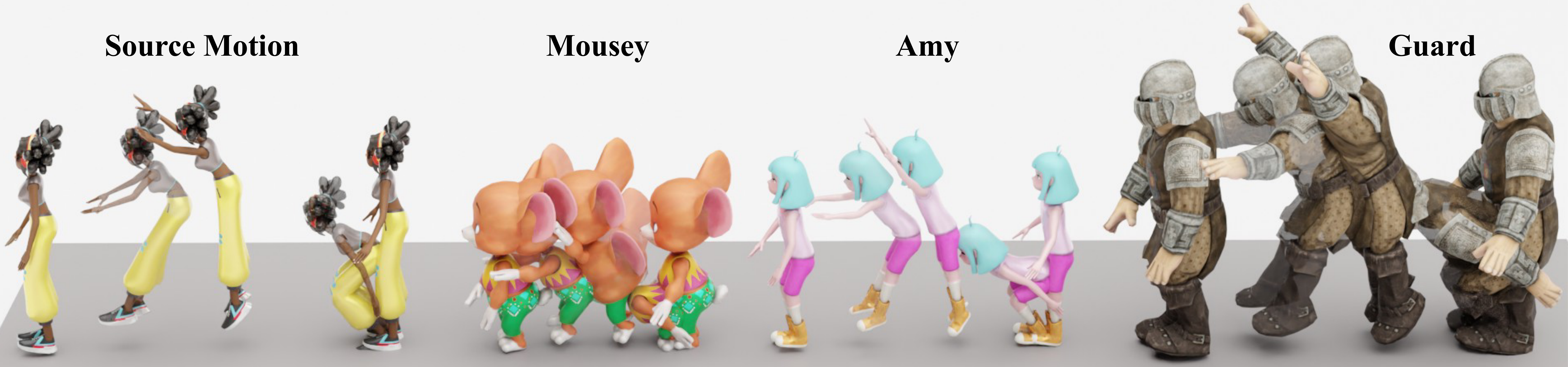
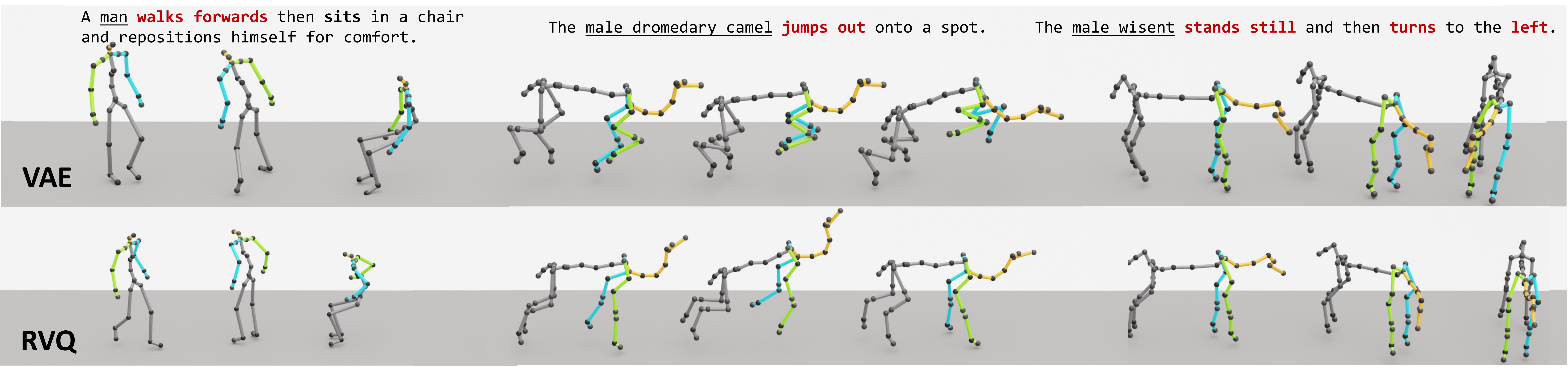
A compact view of the metrics that best communicate the main claims: zero-shot cross-dataset robustness, retargeting fidelity, and text-to-motion learnability. For cross-topology transfer, we highlight global trajectory and joint-position errors because they directly reflect whether the decoded motion remains structurally stable. Lower is better except Top-3.
| Setting | Method | RT | JP | Takeaway |
|---|---|---|---|---|
| Train Human -> Test Animal | SAME | 191.46 | 398.14 | Severe cross-topology drift |
| Ours | 15.593 | 34.585 | Keeps target structure stable | |
| Train Animal -> Test Human | SAME | 110.51 | 122.69 | Struggles with human topology |
| Ours | 57.228 | 80.908 | Better RT/JP fidelity |
| Method | Internal | Cross |
|---|---|---|
| MoMask | 89.421 | 103.72 |
| SAN | 15.9647 | 34.8207 |
| SAME | 1.4842 | 0.9604 |
| Ours (RVQ) | 1.1238 | 0.9669 |
| Ours (VAE) | 0.2122 | 0.1974 |
| Method | FID | MMD | Top-3 |
|---|---|---|---|
| Upper Bound (Ground Truth) | |||
| GT | 0.000 | 2.901 | 0.808 |
| Text-to-Motion Generation | |||
| SAME | 1.628 | 4.661 | 0.554 |
| Ours (VAE) | 1.226 | 4.576 | 0.563 |
| Ours (RVQ) | 0.158 | 3.955 | 0.639 |